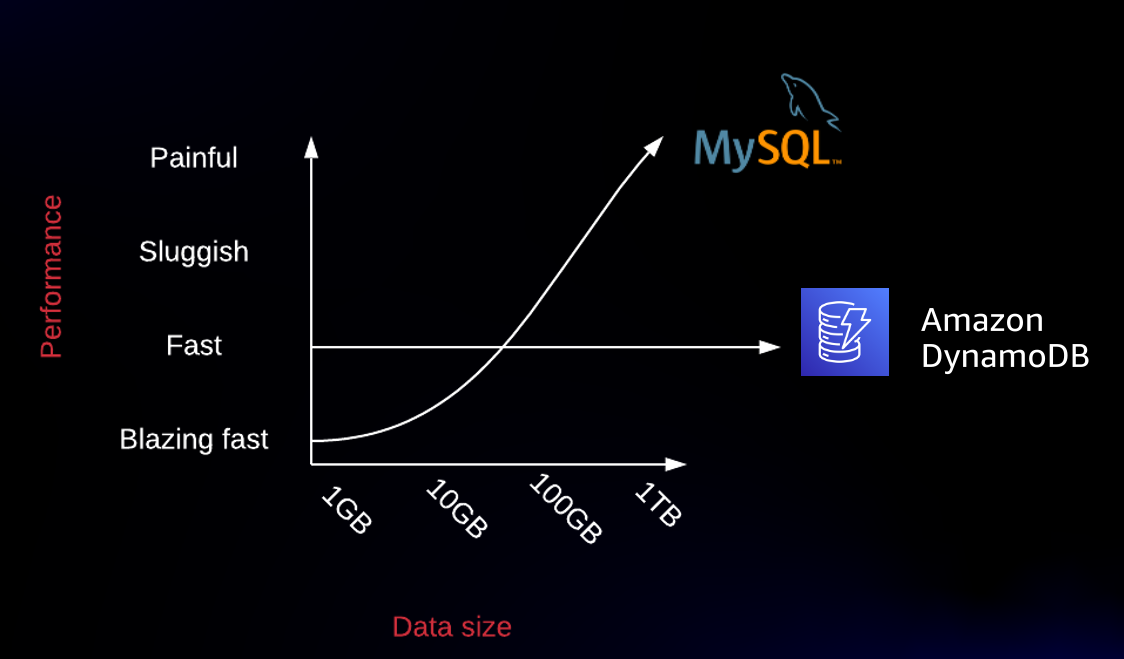
DynamoDB 最讓人稱道的就是他毫秒級的回應速度,無論多少資料量,都能用同等速度回應,Alex DeBrie 就曾經用這張圖很簡單地說明資料量對效能的影響:
 (圖片出處: https://www.alexdebrie.com/posts/dynamodb-paper/)
(圖片出處: https://www.alexdebrie.com/posts/dynamodb-paper/)
但鍊金術告訴我們的原則就是等價交換,雖然 DynamoDB 的承諾是真的,但在辦到之前,需要開發人員大量的前期工作,才能如預期般達到效能,或是在合理的成本中達到。
這些工作,就是需要作好資料塑模(Data Modling)。一般而言,做好資料塑模也沒有什麼好計較的,即便是 MySQL 也是要做這些事,對吧? 問題在於,DynamoDB 為了效能考量,天生就沒有關聯式資料庫的 Join 的機制,但是資料本身又不可能不做關聯,一筆訂單連結不到購買人和售出商品的資訊,即便是像閃電一般快也沒有意義。
也因此,DynamoDB 通常使用 Single Table Design 這個方式,以及透過建立索引,達到和關聯式資料庫使用 Join 等價的效果。沒做好的話,輕則應用程式的反應速度或運作不如預期,重則花費許多預料之外的成本。不過這個細述展開就不得了,暫時在此先打住。
如果你當初覺得學 SQL 的正規化的難度有幾分,這裡的資料塑模難度可能要先乘於 10 吧?我們也可以說,學 DynamoDB 開發其實就是在學好如何以它的邏輯進行資料塑模。
DynamoDB MCP Server 用來協助資料塑模
這個痛點非常的明顯,因此 AWS DynamoDB 團隊從這裡切入,透過 DynamoDB MCP Server 來協助開發人員做資料塑模,我覺得是相當精準的一刀。
你可以用有支援 MCP Server 的編輯器如 Cursor 或是 VS Code 來接上,而官方建議使用像Amazon Q、Anthropic 的 Claude 3.7 Sonnet、Claude 4 Sonnet、OpenAI 的 o3 reasoning model 以及Google Gemini 2.5 作為對話 Model,可以取得較好的結果。設置完成後,只要交談時提及 DynamoDB 的相關關鍵字,就能應用它來進行資料塑模。
在交談中做完塑模與應用程式架構與成本分析
觸發交談後,首先 AI 會針對你的應用程式的需求進行了解,像是比較鳥瞰式的應用程式的作用、規模、存取模式或是實體(Entity)等等。這個目的是為了產生 dynamodb_requirements.md 這一個檔案,檔案內容是根據交談產生的存取模式清單內容,也會分析特定的需求是否適合用 DynamoDB 來處理,進而給出建議。
這個文件當你覺得差不多的時候,就可以進入產生 dynamodb_data_model.md,裡面會設計出必要的 Primary Key、欄位和索引等,而這些就是在開發使用 DyanmoDB 時,開發人員最容易吵架的部分,它不像正規化有一套科學化的檢測標準,你做得對或錯很容易分辨,在 DyanmoDB 中,有時容易誤判,有時是取捨,很難有固定的作法。現在透過 MCP 的指引,也許可以讓開發人員在做事時可以更有自信。
而且除了架構分析,如果你給出足夠的細節,它連成本也都可以算給你看,雖然有時開發人員不太關心這個,但在用 DynamoDB 的時候,請學一下。雖然 DynamoDB 用起來體感偏便宜,但因為它很難被打掛,所以一旦你做了錯誤的設計,也許代價不是網站當機,而是天價的帳單。
應用工具之前或之際,該學的還是要學
因為我也還沒用過,這個能不能完全取代過去一再反覆修改的 DynamoDB 塑模,也沒辦法打包票。但隨著 AI 幾乎每月一迭代的情況,即便現在做得不夠完善,差的也只是時間的問題,也且很可能不會讓人等太久。
但即便如此,開發人員就可以把這個困難的工作完全外包給 AI 了嗎? 我認為當然不是這樣,作為一個開發人員,該學的還是要學。你可以透過 AI 加速工作,但你不能在完全一無所知的情況下來用它,畢竟這次運作的好好的,下次就未必了,出問題的時候,雖然你可能還是會餵給 AI 問問題,但它的回答你是否有足夠的判斷力,我覺得那還是一個合格開發者的基本能力。
所以 DynamoDB 的資料塑模雖然不容易,該付出的學習成本還是不能少。